- Published on
Bulk Download up to 20 TB of Queensland’s Geoscience Data using an API
- Authors

- Name
- Eric McCowan
- @ericrmc

Geoscience data has typically been harder to obtain as it comes from disparate source systems and physical media, and the file sizes — particularly for seismic surveys— can be massive. The Geological Survey of Queensland (GSQ) has recently undergone a data modernisation transformation, and terabytes of geoscience data is now available on their new Open Data Portal (ODP) at https://geoscience.data.qld.gov.au. Work is still underway to bring online vast archives of newly digitised data from literal warehouses — totalling over 120TB — some of which will also make it into the portal.
The data management system GSQ chose for their new data portal was CKAN, a common platform as it has a global user-base, is customisable and open source, and has a robust feature-set and API. GSQ took it to the next level by choosing to use linked data features such as URIs and vocabularies for all their data management and cataloguing. Their CKAN is also configured to use AWS S3 as its back-end storage, which allows for highly available data and incredibly fast speeds, without overloading their servers.
After migrating terabytes of data to the AWS cloud and making it available for the ODP, we noted that power users may want to leverage the CKAN API for bulk searches and downloads instead of navigating pages and clicking buttons. For some of their specialised processes or applications, it is important to have all the data downloaded to local storage, or their own AWS cloud account if they were using EC2 compute resources. However, writing out the API calls in a Python script isn’t for everyone — GSQ have documented it all in their GitHub — so we have provided a workflow and new library/tool to make it easier. Note that not all datasets may be available using this method yet.
To create a list of dataset IDs to download, we will use the GeoResGlobe, available from the landing page of the ODP:
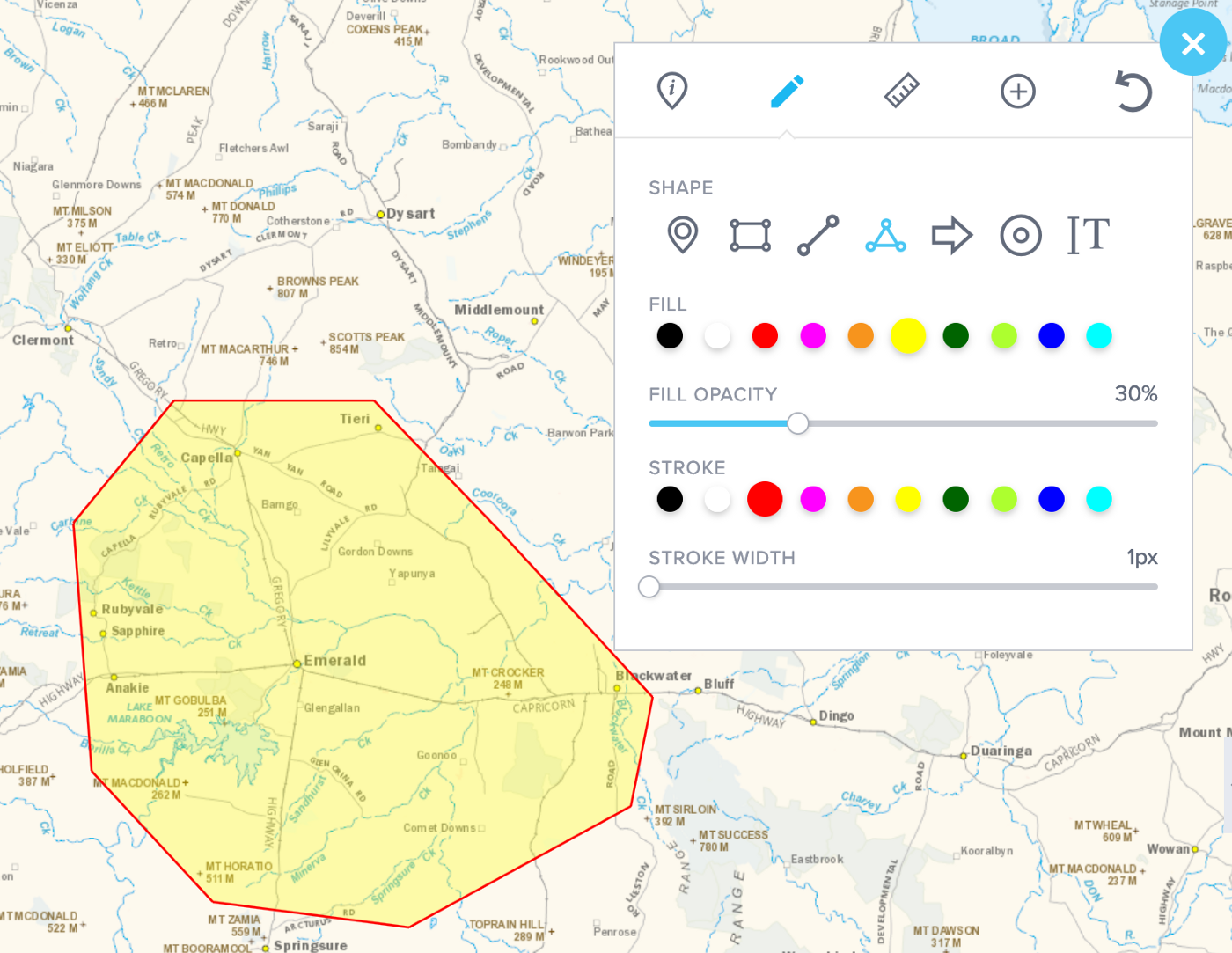
Draw a polygon around your area of interest using the top-right controls. Here we have drawn around Emerald in the Central Highlands:
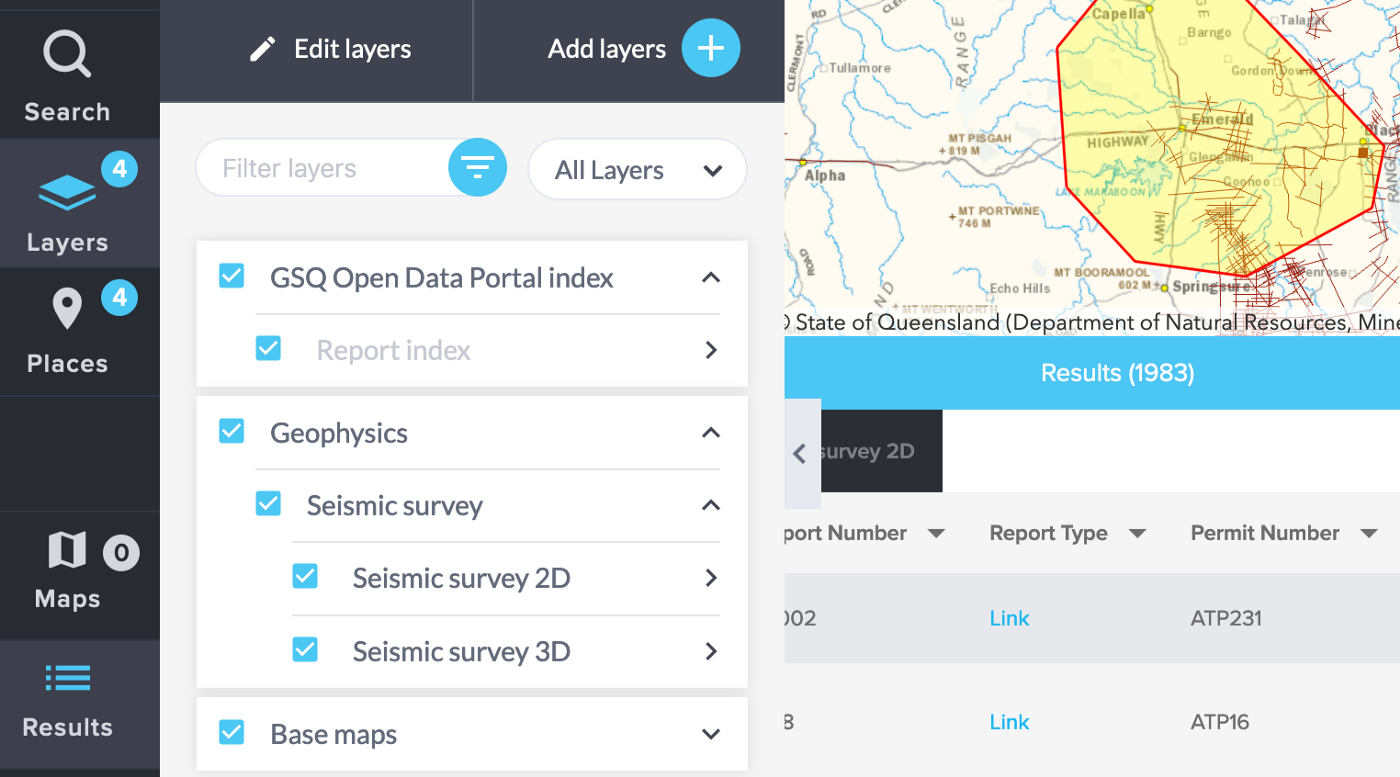
Select the layers you are interested in on the left-hand panel. Here we have selected Seismic survey datasets and Reports permits:
Click Places, then “Query layers using this place”. A new panel will appear at the bottom with a table for each layer available. Use the down-arrow button to download a CSV format file for each table you need data for. The PID field, if it exists, is the dataset’s Persistent Identifier that matches the ODP.
Now that we’ve got a big list of datasets to download, we need to bring in the new ckan-downloader Python tool from PyPI. Get the latest Python version from https://www.python.org/downloads/ and then install the tool with pip install ckan-downloader in your terminal or command prompt.
Run python -m ckan_downloader to start the interactive tool. You will need to repeat this for each CSV — you are free to combine them into a single table as long as the PID field persists. Follow the prompts to enter the following:




What is the data portal URL?
> geoscience.data.qld.gov.au
Test connection to https://geoscience.data.qld.gov.au/api/action/site_read was successful.
Do you have a CSV with the dataset IDs to download? (y/n)
> y
What is the CSV file path?
> csvfiles/Report Index_wkid_GDA 2020.csv
Does this CSV have a header row? (y/n)
> y
The name of the field/column containing the dataset IDs is needed. The options are:
LAT, LONG, qldglobe_geometry, PID, Report Title, Report Number, Report Type, Permit Number, Commodity, Report Period Start Date, Report Period End Date, Stratigraphy, Open File Date, Submitter
Which field has the IDs?
> PID
Which directory should the downloads be saved in?
> downloads
Starting dataset cr050948
Downloading CR050948 Report Geometry (https://geoscience.data.qld.gov.au/dataset/...25252f50948.zip) to downloads/cr050948/50948.zip
Downloading PRODUCTION TESTING REPORT (https://gsq-horizon.s3-ap-southeast-2.amazonaws.com/QDEX/50948/cr_50948_2.pdf) to downloads/cr050948/cr_50948_2.pdf
Downloading Report_Main_50948 (https://geoscience.data.qld.gov.au/dataset/...Report_Main_50948.json) to downloads/cr050948/Report_Main_50948.json
Starting dataset cr065229
...
Once that process is finished, you will have transferred all your datasets of interest from the GSQ Open Data Portal cloud storage to your own local device or cloud storage. More features can be added to the tool to enable completely automated interactions, which may be useful if you wish to routinely query for new datasets in a region without even visiting the website. If there is interest we can update the tool and write an updated guide.